
JION
테이블 간의 수평적 결합이다.
여러 테이블에 각각 나누어져서 정의된 속성(컬럼)을 동시에 조회할 경우에 사용한다.
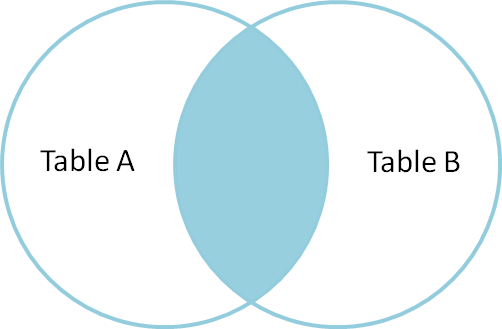
1) EQUI JOIN
JOIN에 사용되는 테이블의 컬럼간에 정확히 일치(EQUAL)하는 데이터를 return 한다.
EQUAL( = ) 연산자를 사용하여 JOIN 한다.
|
SELECT dname,ename,job,sal FROM emp,dept WHERE emp.deptno=dept.deptno AND /* -> JOIN 조건 */ emp.job IN ('MANAGER','CLERK') /* -> 필터링 조건 */ ORDER BY dname; |
쿼리 실행순서: 필터링 조건 > JOIN 조건
2) NON EQUI-JOIN
EQUAL( = ) 이외의 연산자, 어떤 범위(<, >, BETWEEN, IN)를 사용하여 JOIN
|
SELECT E.ename, E.job, E.sal, S.grade FROM emp E, salgrade S WHERE E.sal BETWEEN S.losal and S.hisal AND E.deptno IN (10,30) ORDER BY E.ename;
|
3) OUTER-JOIN
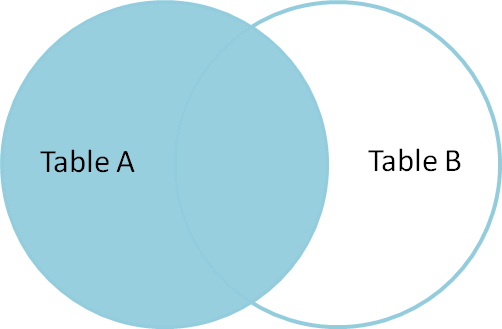
(INNER) JOIN 조건에 직접 만족되지 않는 정보도 포함해서 조회한다.
정상적으로 JOIN 조건을 만족하지 못하는 행을 보기 위해 사용한다.
어떤 집합을 기준으로 JOIN되는 다른 집합과의 연결에 실패했더라도 그 결과를 추출하는 조인이다.
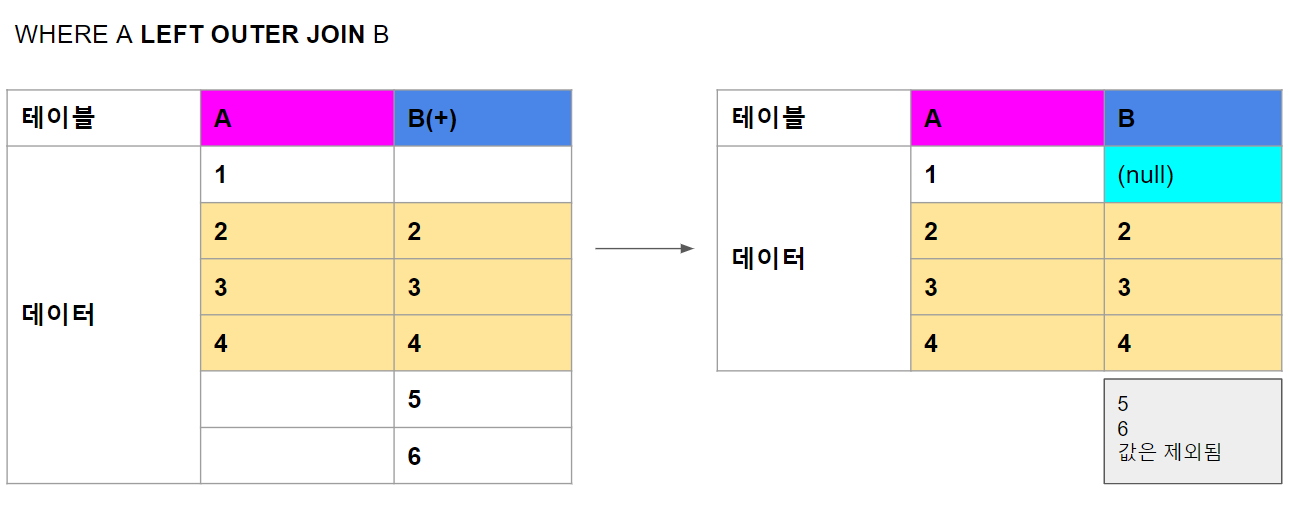
B에는 1값이 없어 null로 채워져서 나온다.
B의 5, 6값은 A에 없는 값이므로 JOIN에 실패하여 제외된다.
|
SELECT D.dname, E.ename, E.job, E.sal FROM emp E, dept D WHERE E.deptno(+) = D.deptno /* -> EQUAL하는 데이터가 없는 테이블에 (+) 한다. */ ORDER BY D.dname; |
=> OUTER JOIN 의 연산자 (+) 는 JOIN 시킬 값이 없는 테이블측에 (+)를 위치시킨다.
|
SELECT * FROM dept D LEFT OUTER JOIN emp E /* -> LEFT(왼쪽) 테이블을 기준으로 합친다. */ ON E.deptno = D.deptno ORDER BY D.dname; |
4) SELF JOIN
동일 테이블 간의 컬럼을 이용한 조인 방법이다.
|
SELECT E.ename, M.ename FROM emp E, emp M /* -> E: eployeer(직원 테이블), M: manager(매니저 테이블)*/ WHERE E.mgr=M.empno ORDER BY M.ename; |
결국, 각 직원을 담당하는 매니저의 이름을 구할 수 있는 쿼리이다.
직원->사수의 사번->매니저의 사번->매니저의 이름
CARTESIAN PRODUCT
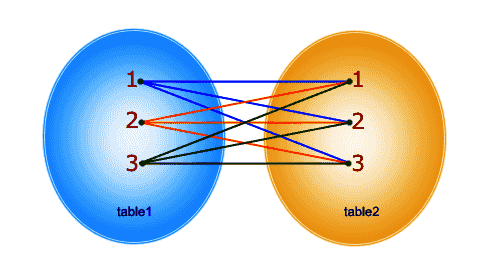
JOIN을 잘못할 경우 데카르트의 곱집합이 일어난다.
1) 조인조건이 없는 경우
| SELECT ename, job, dname FROM emp, dept; |
결론: emp 테이블의 튜플 수 * dept 테이블의 튜플 수
2) 조인조건은 없고, 필터링 조건만 있는 경우
| SELECT ename,job,dname FROM emp,dept WHERE emp.sal>2000 AND dept.deptno IN (10,20); |
결론: 필터링 조건을 만족하는 각 튜플 수의 곱
SELECT * FROM emp WHERE emp.sal>2000;
SELECT * FROM dept WHERE dept.deptno IN (10,20);
3) 조인조건이 잘못된 경우
| SELECT E.ename, E.job, E.sal, S.grade FROM emp E, salgrade S WHERE E.sal < S.losal AND E.deptno IN (10,30) ORDER BY E.ename; |
결론: 10번 30번 부서 번호를 가진 사원중 / 급여가 급여등급표의 최소급여 보다 작은 경우 모두 / 급여등급 테이블과 OUTER JOIN
SUBQUERY
다른 SQL(SELECT, INSERT, DELETE, UPDATE, CREATE..) 문 안에 포함된 SELECT 문이다.
1) Scalar Subquery
1행, 1컬럼의 값 리턴, SELECT에서 사용한다.
|
/* 사원이 근무하는 부서의 이름 */ SELECT E.ename, (SELECT dname FROM dept d where E.deptno=D.deptno) AS COL |
2) Inline View
FROM 절에 테이블 대신 사용한다.
SQL 실행되는 시점에 동적으로 생성되는 View 역할을 한다. => Dynamic View
|
/* 직무별 평균급여 보다 많이 받는 사원의 정보 */ SELECT deptno, ename, emp.job, sal, IV.AVG_SAL |
3) Nested Subquery
WHERE 조건절에 사용한다.
|
/* 3명 이상 근무하는 부서의 정보 */ SELECT dname, loc FROM dept (SELECT deptno FROM emp HAVING COUNT(*) > 3); |
TRANSACTION

데이터베이스의 상태를 변화시키기 위해서 수행하는 일련의 작업 단위를 말한다.
데이터베이스의 상태를 변화 => DML 연산의 묶음이다.
[ 데이터 조작어(DML) ]
- INSERT
- UPDATE
- DELETE
- MERGE
[ 트랜잭션의 특징: ACID ]
원자성(Atomicity): 트랜잭션 실행 도중에 문제가 발생했을 경우, 중단된 상태가 모두 실패하거나, 모두 완성시키는 둘 중 하나의 상태가 되어야 한다.
All or Nothing.
작업 단위를 일부분만 실행하지 않는다.
|
100개 DML로 구성된 트랜잭션 중 99개 완료, 1개 실패가 된다면? => 무조건 실패로 간주 => 트랜잭션 시작 전 상태로 돌린다. 100개가 모두 성공했을 시 트랜잭션이 성공한다. 중간상태란 없다. |
일관성(consistency): 트랜잭션 완료 후에도 데이터베이스가 일관된 상태로 유지되어야 한다.
|
A --(계좌이체)▶ B A계좌 잔액 + B계좌 잔액 = 트랜잭션 실핸 전(A가 B에게 계좌이체 하기 전)의 합과 동일해야 한다. |
고립성(Isolation): 하나의 트랜잭션이 실행하는 도중에 변경한 데이터는 이 트랜잭션이 완료될 때까지 다른 트랜잭션이 끼어들지(참조하지) 못하도록 보장한다.
트랜잭션끼리는 서로를 간섭할 수 없다.
|
하나의 트랜잭션이 A 계좌에서 작업을 하고 있다면, 다른 트랜잭션이 A계좌에 대해 연산하거나 참조하거나 관여할 수 없다. 먼저 진행중인 트랜잭션 작업이 끝날 때까지 대기해야 한다.
데이터를 읽거나 쓸 때는 문을 잠궈서 다른 트랜잭션이 접근하지 못하도록 고립성을 보장하고, 수행을 마치면 unlock을 통해 데이터를 다른 트랜잭션이 접근할 수 있도록 허용하는 방식이다.
트랜잭션에서는 데이터를 읽을 때, 여러 트랜잭션이 읽을 수 있도록 허용하는 shared_lockd을 한다. 즉, shared_lock은 데이터 쓰기를 허용하지 않고, 오직 읽기만 허용한다.
데이터를 쓸 때는 다른 트랜잭션이 읽을 수도 쓸 수도 없도록 하는 exclusive_lock을 한다. 그리고 읽기, 쓰기 작업이 끝나면 unlock을 통해 다른 트랜잭션이 lock을 할 수 있도록 데이터에 대한 잠금(lock)을 풀어준다.
그런데 lock와 unlock을 잘못 사용하면 데드락(deadlock)상태에 빠질 수 있다. 그렇게 되면 모든 트랜잭션이 아무것도 수행할 수 없는 상태가 된다. |
지속성(Durability): 트랜잭션이 완료되면, 주기억장치가 아닌 디스크와 같은 보조기억장치에 저장되거나 그렇지 않더라도 시스템 장애가 회독되고 난 루에 어떠한 형태로든지 그 데이터를 복구 할 수 있게 해야한다.
'빅데이터 > 개념 정리' 카테고리의 다른 글
| 메모리 구조에 대하여, 코드는 어떻게 실행되는걸까? (0) | 2019.08.28 |
|---|---|
| HashMap(해쉬맵)에 대한 개념과 사용방법 (0) | 2019.08.26 |
| Null, DISTINCT, DECODE, CASE, 오라클 함수 (0) | 2019.08.13 |
| 데이터베이스의 기초, DBMS (0) | 2019.08.12 |
| docker에 대하여, 왜 인기일까? (0) | 2019.08.08 |



